
KLASIFIKASI DIALEK BAHASA JAWA MENGGUNAKAN METODE NAIVES BAYES
Abstract
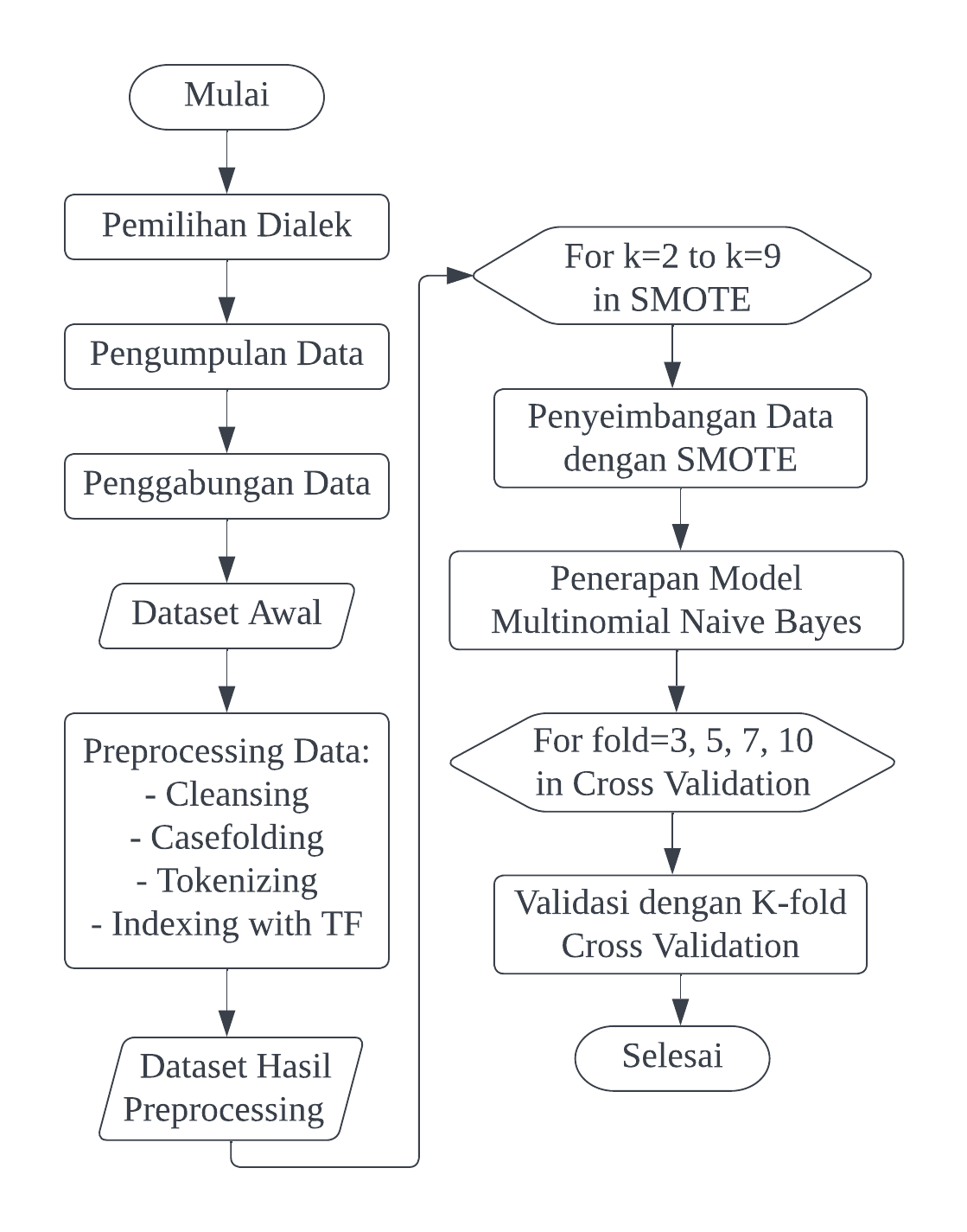
Pulau Jawa merupakan pulau terpadat di Indonesia dan memiliki keragaman dialek yang tinggi. Berdasarkan peta bahasa yang dikeluarkan oleh KEMDIKBUD, Pulau Jawa memiliki 12 dialek utama yang tersebar di Jawa Timur, Jawa Barat dan Jawa Tengah. Dari hasil survei yang telah dilakukan, dialek yang digunakan sebagai dataset hanya dibatasi menjadi 3 dialek terpopuler dari setiap provinsi yaitu Dialek Cirebon, Dialek Tegal dan Dialek Jawa Timur. Penyediaan data dilakukan dengan metode studi literatur yang bersumber dari buku dan dokumen tertulis yang tersedia di internet. Data akan diolah dan dianalisis menggunakan algoritma Multinomial Naives Bayes karena cepat dalam proses perhitungan, sederhana dan memiliki akurasi yang tinggi. Algoritma akan diuji menggunakan K-fold Cross Validation untuk mengetahui performa algoritma Multinomial Naives Bayes dalam melakukan klasifikasi dialek di Pulau Jawa. Metode Synthetic Minority Over-Sampling Technique (SMOTE) juga digunakan dalam penelitian ini untuk mengetahui pengaruh teknik oversampling terhadap performa algoritma. Dari penelitian in dihasilkan performa terbaik dengan akurasi sebesar 96,97%, presisi sebesar 97,53% dan recall sebesar 96,83%.
Downloads
Copyright (c) 2022 Grace Angeline, Aij Prasetya Wibawa, Utomo Pujianto

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
















